

We already know that ChatGPT is an Artificial Intelligence (AI) powered chatbot, which is based on large language module, which has garnering skyrocketing popularity. But its Visual counterpart has taken things to a next level.
Following the stellar response to ChatGPT and its integration into Microsoft’s search engine Bing, Microsoft has gone ahead and released Visual ChatGPT which makes things more interesting. Let’s take a look at its functioning and how is it different from the regular version.
Visual ChatGPT – What Is It, and How Is It Different?
Visual ChatGPT is a system that includes multiple visual foundation models, which lets users to communicate with ChatGPT through graphical user interfaces. While ChatGPT is only based on language module powered by AI, the Visual ChatGPT includes works on visuals.
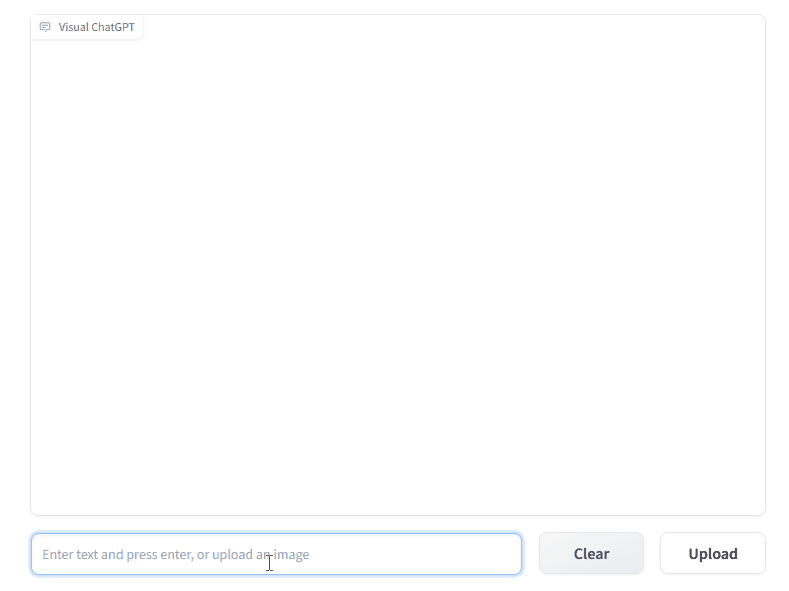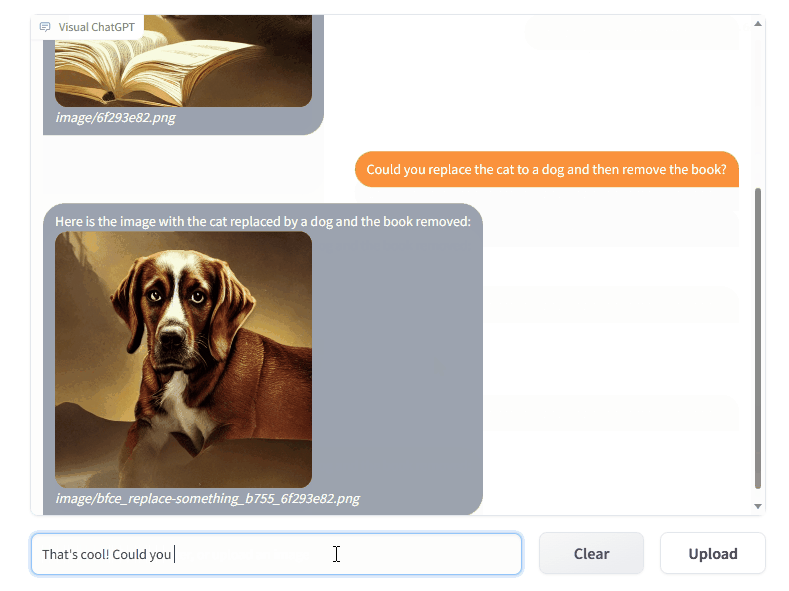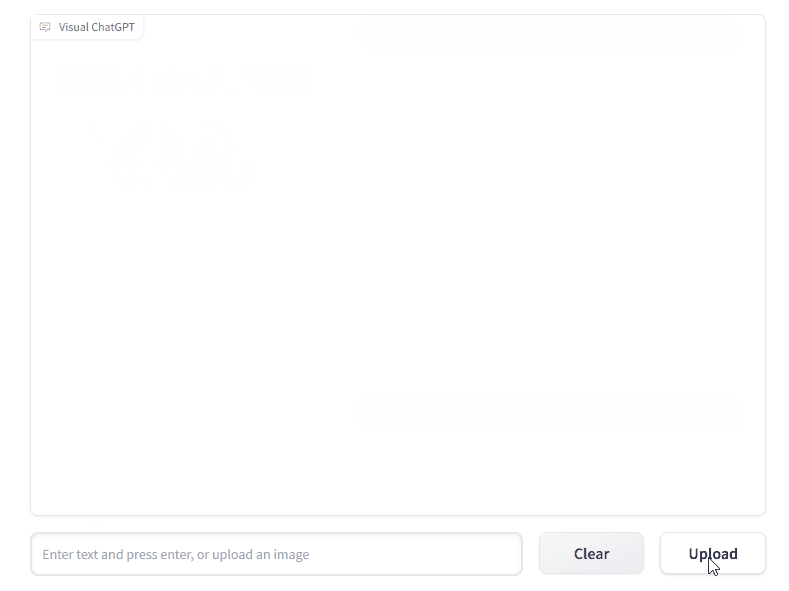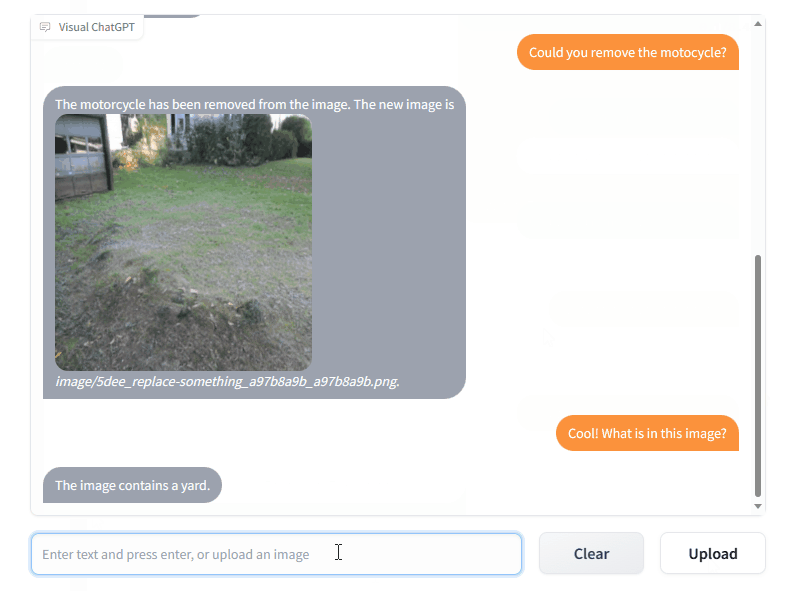
The Visual ChatGPT combines different types of visual foundation models, including ControlNet, Transformers and Stable Diffusion along with the ChatGPT foundation, which allows the chatbot to recognize and interpret images. This allows the AI module to successfully interact with users and offer image generation as well as editing.
ChatGPT’s massive popularity is primarily because of its ability to engage with the user in a human-like conversation. The possibilities of its vast and varied applications has sparked interest in users ranging from general internet browsers to serious researchers. In its current form, it only responds to and in texts. This means it can only process and generate texts and not images. This linguistic learning module restricts it from processing or generating any visuals.
On the other hand, the visual foundation models like Visual Transformers and Stable Diffusion are excellent in terms of visual processing as well as generating. Hence, Visual ChatGPT is nothing but the integration of these visual models with ChatGPT. Combining the linguistic and visual models offer the best of the two worlds, and offers a very new and improved model – Visual ChatGPT, that can process and generate visual inputs.
Hence, Microsoft researchers have developed Visual ChatGPT, which integrates many visual foundation models and lets users to interact with ChatGPT not only with texts, but also with images.
The Visual ChatGPT is capable of and not limited to :
- Transmitting and receiving not only text but also images.
- Respond to complex visual questions and/or visual editing instructions.
- Offering inputs on visuals and request corrections.
The training of a multimodal conversational model is a highly sophisticated and logical way to construct a system that is comparable to ChatGPT, that is capable of perceiving and generate visual information. However, creating such a complex and multifunctional sophisticated module requires the integration large amounts of data and processing abilities.
Till now, ChatGPT is facing some issues during long duration of conversations, and the Visual ChatGPT is also susceptible to errors. However, the system is expected to be much more efficient in the near future.
